继龙虾(OpenClaw),爱马仕(Hermes Agent)之后,开源人类(OpenHuman)登场。
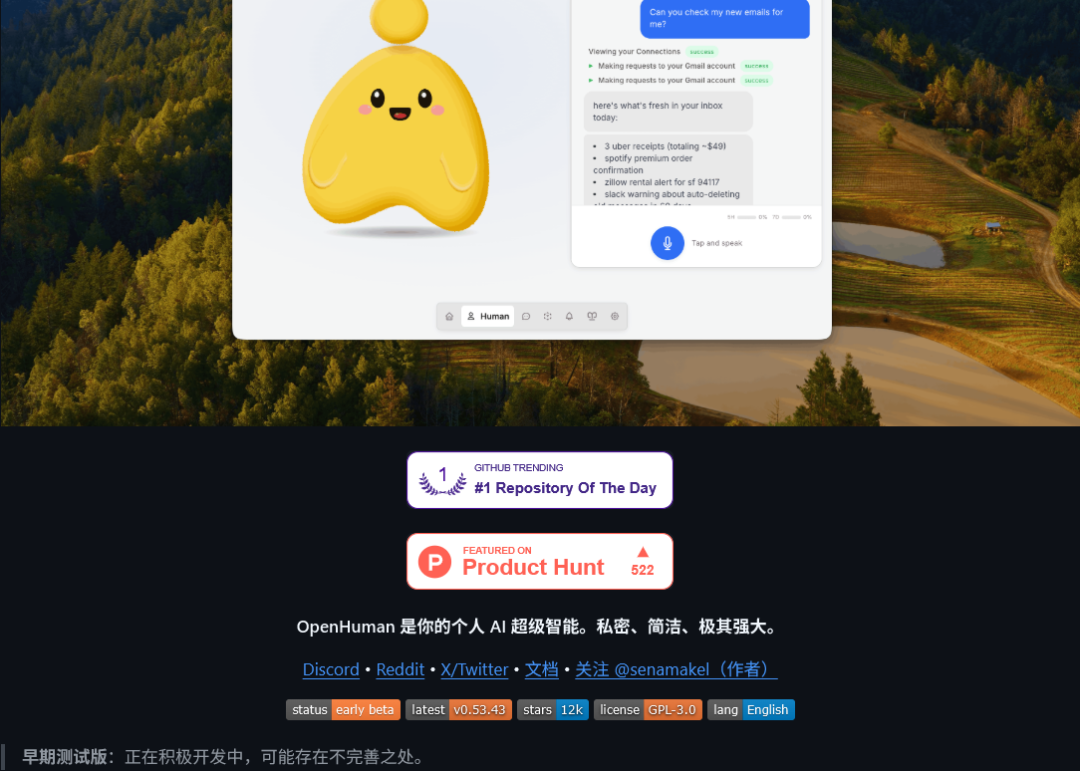
OpenHuman 是由开发者团队 tinyhumansai 构建的一个开源桌面 AI 智能助手。
tinyhumansai 团队自称为“专注于创建接近人工意识的 AI 算法的 AI 实验室”,其愿景远超一般的开发工具,他们试图构建具有人工潜意识的 AI 代理。这种对人工意识和持久记忆的追求,构成了 OpenHuman 的底层精神内核。
官方定位简洁而有力:你的个人 AI 超级智能,私密、简洁、极其强大。
该项目采用 GNU 许可证开源,基于 Tauri 桌面框架构建,TypeScript(前端)与 Rust(核心层)技术栈,旨在打造一个真正融入用户日常生活的 AI 代理应用。
与大多数从聊天框出发的 AI 助手不同,OpenHuman 的设计哲学是:一个 AI 助手只有具备了用户的上下文信息,才能真正发挥作用。
它不是简单地提供一个与大型语言模型对话的界面,而是一个集成了桌面 UI、第三方服务集成、持久记忆系统、智能工具集、模型路由、语音功能和可选本地 AI 支持的个人 AI 中枢。
该项目目前处于早期测试(Early Beta)阶段,但其野心之大、功能之丰富,使其在开源社区引起了巨大反响。
最近几日的 GitHub Trending 排行中持续霸榜,每日1600+星标。
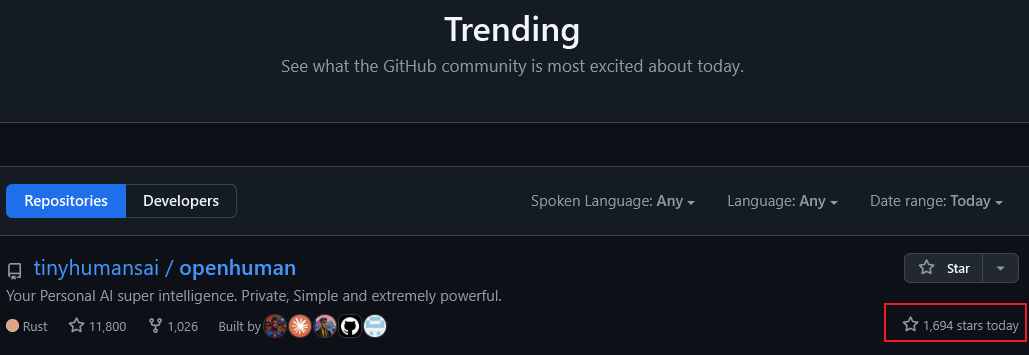
而 TrendShift 的数据也显示该项目获得了异常活跃的社区关注。与此同时,OpenHuman 还登上了 Product Hunt 的精选推荐,社交媒体(X/Twitter、Reddit、Instagram)广泛讨论。
为什么会火?
OpenHuman 的爆火,是因为它精准地击中了当前 AI 助手市场的多个核心痛点。
AI 助手失忆问题。 当前的主流 AI 助手,无论是 ChatGPT、Claude,还是各种编码助手,都无法在对话之间保持关于用户的持久记忆。OpenHuman 通过记忆树(Memory Tree)系统解决了这个问题,让 AI 能够在数分钟内建立起对用户的全面了解。
集成碎片化。 开发者和技术从业者日常使用大量不同的工具和服务,例如 Gmail 处理邮件、GitHub 管理代码、Slack 进行沟通、Notion 记录笔记、Jira 跟踪任务、Calendar 管理日程。现有的 AI 助手要么不支持这些集成,要么需要用户手动搬运数据。OpenHuman 提供了 118 个以上的 OAuth 一键集成,并自动以 20 分钟为周期拉取数据。
隐私焦虑。 随着用户将越来越多的个人和工作数据交给 AI 服务,数据隐私问题日益突出。OpenHuman 采用了本地优先(Local-First)策略,所有记忆数据存储在用户本机的 SQLite 数据库中,而非云端服务器。数据经过本地加密处理,始终归用户所有。
成本与效率。 大型语言模型的 API 调用费用高昂,而大量 token 被浪费在冗余信息上。OpenHuman 引入了 TokenJuice 智能压缩技术,在数据触达 LLM 之前进行预处理(HTML 转为 Markdown、长 URL 缩短、非 ASCII 字符移除),最多可降低 80% 的 token 消耗和成本。
上手门槛高。 大多数 AI 代理框架(如 LangChain、AutoGen)都需要大量的配置、编程知识或命令行操作。OpenHuman 采用了零配置理念,提供清爽的桌面 UI,用户从安装到拥有可用智能体仅需几次点击。
TechTimes 报道中使用了反转剧本(Inverting the Playbook)这一措辞来描述 OpenHuman:在用户输入第一个提示之前就已经了解用户。
核心技术深度解析
记忆树是该项目与其他所有 AI 助手最根本的区别。
记忆树的工作原理如下:用户连接的各个数据源(邮件、日历、代码仓库、文档、消息等)中的所有内容,都会被规范化为不超过 3000 token 的 Markdown 片段。这些片段经过质量评分后,被折叠成层级化的摘要树结构。最终的数据存储在用户本机的 SQLite 数据库中,形成一个完全属于用户的知识库。
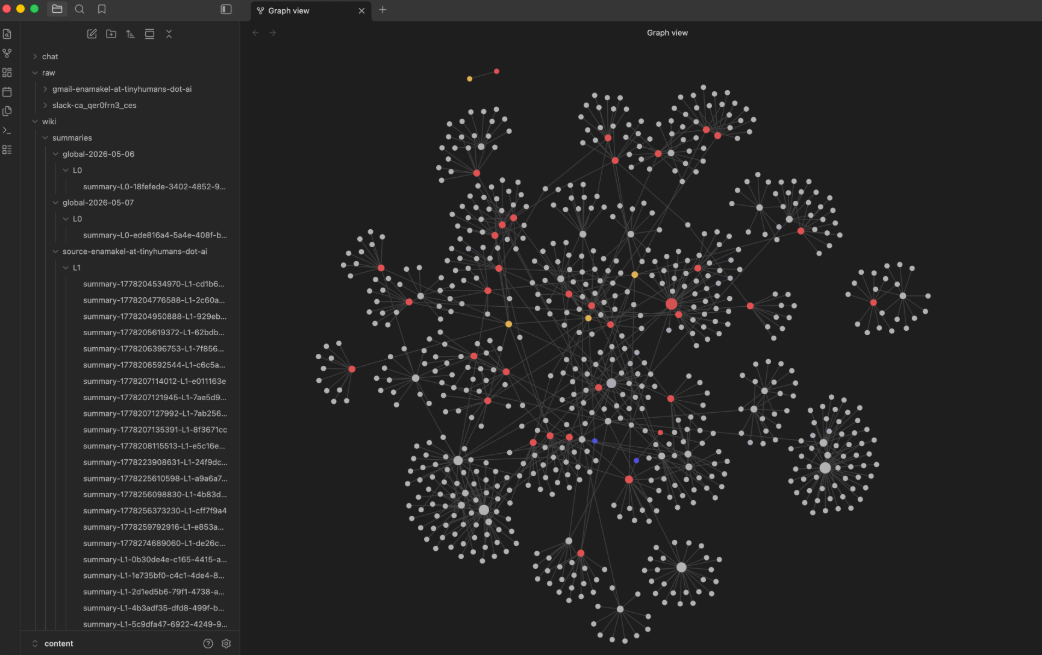
这种设计的灵感直接来源于 AI 领域著名研究者 Andrej Karpathy 的 LLM 知识库工作流。
Karpathy 曾在社交媒体上分享了他使用 Obsidian 构建 LLM 个人知识库的方法,而 OpenHuman 将这一理念产品化,并将其自动化。
与记忆树配合的是 Obsidian Wiki 集成。相同的 Markdown 片段会以 .md 文件的形式输出到兼容 Obsidian 的仓库中。这意味着用户可以使用 Obsidian(最受欢迎的个人知识管理工具之一)直接浏览、搜索和编辑 AI 的记忆库。
这种设计赋予了用户对 AI 知识的完全透明度和控制权,同时也意味着用户可以在不依赖 OpenHuman UI 的情况下管理和审查 AI 的记忆内容。
此外,OpenHuman 还提供了可选的 agentmemory 后端支持,允许用户将记忆存储与 Claude Code、Cursor、Codex、OpenCode 等编码助手共享,实现跨工具的统一记忆。
记忆树需要数据喂养,而自动拉取机制确保了数据的新鲜度。OpenHuman 的核心服务每 20 分钟遍历所有活跃的连接,将新数据拉入记忆树中。这意味着用户无需编写轮询循环,无需设计同步策略,AI 在每天早上就已经拥有了当天的上下文。
这一机制将 AI 助手从被动响应模式转变为主动感知模式。
传统的 AI 助手像是被关在房间里的顾问,只有你推门进去提问时它才能工作;而 OpenHuman 的 AI 更像是一个始终在你的工作环境中观察、学习的助手,即使你停止输入,它仍然在后台持续思考和整合信息。
OpenHuman 目前支持 118 个以上的第三方服务集成,覆盖了用户日常工作的方方面面:
通信工具:Gmail、Slack
项目管理:Linear、Jira
知识管理:Notion、Google Drive
开发工具:GitHub
日程管理:Google Calendar
支付服务:Stripe
消息渠道:支持通过用户日常使用的渠道进行收发
所有集成均通过一键 OAuth 授权完成,每个连接以类型化工具的形式暴露给智能体。这意味着 AI 不仅知道这些服务中有哪些数据,还能理解数据的结构化含义,并据此执行精确的操作。
TokenJuice 是 OpenHuman 在效率和成本控制方面的重要创新。在每一个工具调用、网页抓取结果、邮件正文和搜索载荷触达 LLM 之前,都会经过这一压缩层:
HTML 内容被转换为精简的 Markdown 格式
冗长的 URL 被智能缩短
非 ASCII 字符被移除
冗余格式信息被剥离
TokenJuice 最多可降低 80% 的 token 消耗。
OpenHuman 的模型路由功能是其成本效益的另一个关键维度。不同于将所有任务发送给同一个模型的简单模式,OpenHuman 在一个订阅下将不同类型的任务智能分派到最合适的 LLM:
推理型模型:处理复杂的逻辑推理和分析任务
快速型模型:处理简单的对话和快速响应
视觉型模型:处理图像理解和多模态任务
这种任务级别的模型路由策略,既保证了任务处理的质量,又避免了将昂贵的高性能模型用于简单任务的资源浪费。
OpenHuman 的 UI 设计也颇具特色。它配备了一个桌面吉祥物,一个会说话、能感知周围环境的虚拟形象。
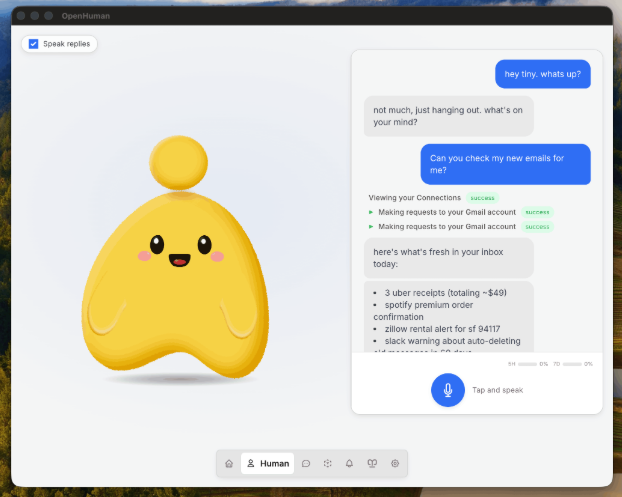
这个吉祥物可以作为真实参与者加入用户的 Google Meet 会议。结合原生语音功能(STT 输入、ElevenLabs TTS 输出、口型同步),OpenHuman 正在模糊 AI 助手与数字伴侣之间的界限。
对于对隐私有更高要求的用户,OpenHuman 支持通过 Ollama 使用本地 AI 模型处理端侧工作负载。敏感任务可以在不发送数据到云端的情况下完成,进一步强化了项目的本地优先理念。
与其他框架对比:

分钟级建立上下文,是 OpenHuman 最革命性的优势。
传统的 AI 助手或代理框架,都需要一个漫长的训练期。无论是通过反复对话提供背景信息,还是通过插件逐步注入上下文,用户都需要花费数天甚至数周的时间,AI 才能对用户的技术栈和工作流有足够的了解。
OpenHuman 通过一键连接账户 + 自动拉取 + 记忆树的组合,将这一过程缩短到几分钟。首次同步完成后,AI 就拥有了用户收件箱、日历、仓库、文档、消息的完整(压缩后的)上下文。
在数据隐私日益受到重视的今天,OpenHuman 的本地优先策略是一个强有力的差异化因素。所有工作流数据保留在用户设备上,经过本地加密,始终属于用户。用户不依赖任何第三方云服务来存储个人记忆,也不必担心数据被用于训练模型或被未授权方访问。
同时,Obsidian Wiki 的导出格式确保了数据的可移植性,即使不使用 OpenHuman,用户仍然可以访问和利用已经构建的知识库。
当前 AI 代理市场的一个显著问题是供应商碎片化。用户需要为不同的 AI 工具分别管理 API 密钥、订阅和配置。
OpenHuman 通过单一订阅 + 内置模型路由的策略,让用户不再需要为选择哪个模型而烦恼。系统会根据任务类型自动选择最合适的模型,在质量、速度和成本之间取得最优平衡。
OpenHuman 的爆火不是偶然的。它代表了一种日益强烈的需求:人们需要的不是一个能对话的工具,而是一个真正了解自己、能持续学习、能跨越工具边界行动的个人 AI 伙伴。
在一个 AI 助手市场被对话式思维主导的时代,OpenHuman 通过记忆树、自动拉取和 Obsidian Wiki 的组合,开辟了一条上下文优先的新路径。
它反转了传统的剧本——不再是用户不断教导 AI,而是 AI 主动学习用户。


